Einführung in Voyage AI
Wusstest du, dass KI-Abfragen deutlich präzisere Ergebnisse liefern, wenn du sie mit relevanten Informationen aus deiner Datenbank anreicherst? Diese Technik nennt sich RAG.
RAG
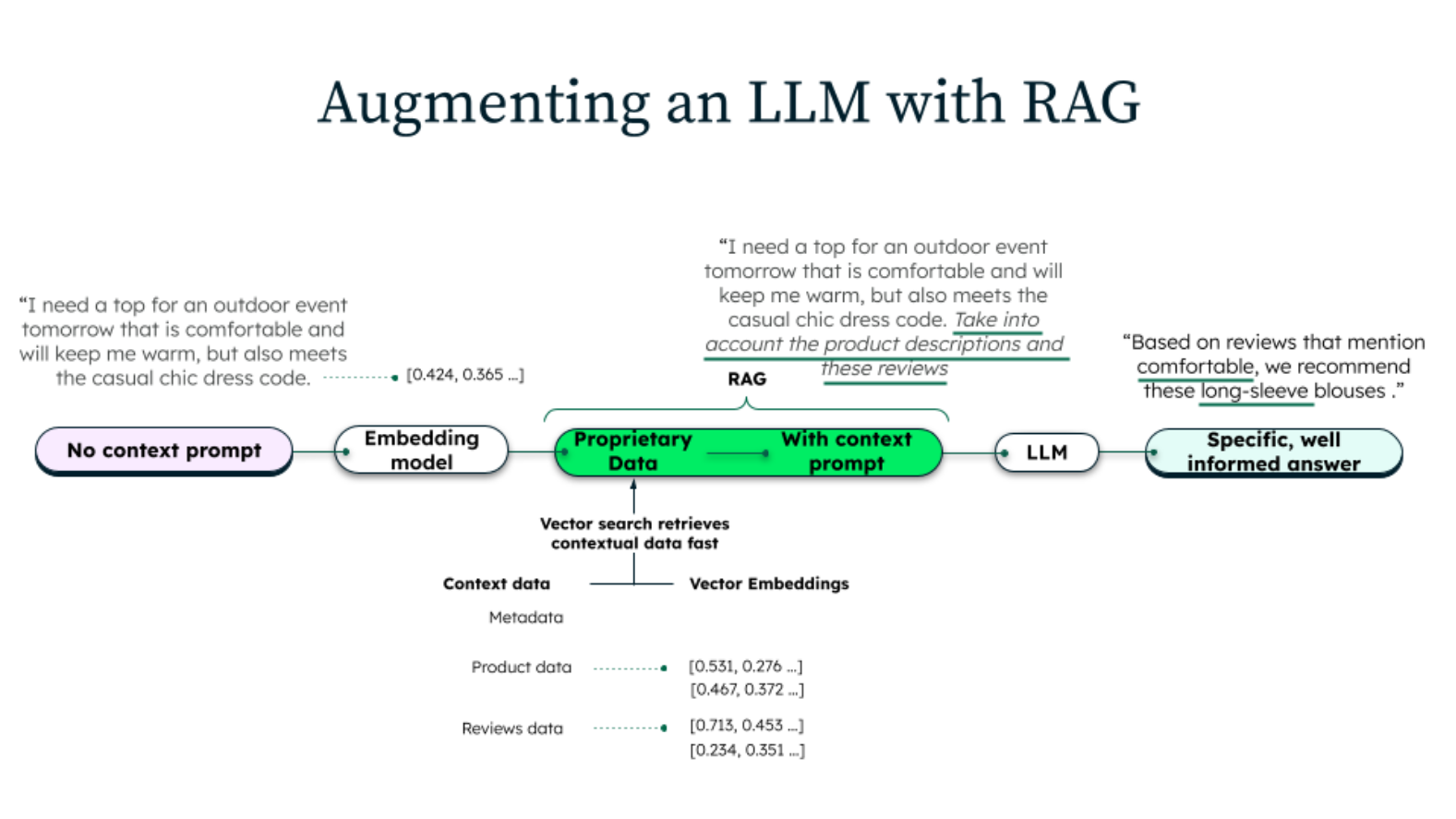
RAG steht für Retrieval Augmented Generation und bezeichnet eine KI-Technik bei der eine Textanfrage an ein LLM (Large Language Model) um weitere Informationen aus einer Datenbank angereichert wird. Die Antwort des LLMs fällt dadurch deutlich spezifischer aus. RAG kombiniert zwei Ansätze:
- Retrieval: Das System durchsucht eine Datenbank, um spezifische Informationen zu einem gegebenen KI-Anfrage zu finden. Typischerweise enthält diese Datenbank Daten, die die Anfrage in einen genaueren und spezifischen Kontext setzen.
- Generation: Nach dem Retrieval-Schritt wird die KI-Anfrage, angereichert um spezifische Informationen aus der Datenbank, an das LLM gesendet. Die Ziel ist eine präzisere Antwort zu erhalten.
Die Idee hinter RAG ist, dass KI-Anfragen nicht nur auf LLMs basieren sollten, sondern zusätzlich über Wissensdatenbanken mit zusätzlichen Informationen angereichert werden sollten. Dadurch können LLMs genauer auf spezifischer antworten.
Ein Beispiel: Wenn du eine Frage zu einem speziellen Thema stellst, könnte RAG zuerst relevante Artikel oder Abschnitte aus einer umfangreichen Datenbank abrufen, deine Anfrage um diese Informationen anreichern, um dann eine fundiertere Antwort über ein LLM zu generieren. Wie funktioniert nun RAG technisch?
Embeddings
Eine Texteingabe für ein LLM muss zunächst mithilfe eines sogenannten Embeddings in einen Vektor aus Zahlen umgewandelt werden. Dieser Vektor repräsentiert die Texteingabe und hilft dabei, relevante Dokumente aus einer Datenbank zu finden.
Die Suche nach relevanten Dokumenten kann jedoch nur durchgeführt werden, wenn die Dokumente in der Datenbank ebenfalls mit Vektoren versehen wurden, die sie repräsentieren, da die Suche anhand dieser Vektoren erfolgt.
Die Vektoren der Datenbankdokumente werden als Datenbankindex implementiert, d. h., jedes Mal, wenn ein Dokument hinzugefügt oder verändert wird, wird der entsprechende Vektor in der Datenbank aktualisiert.
Über den Vektor einer Texteingabe können nun die Dokumente gefunden werden, die zur Texteingabe relevant sind. Diese werden dann zusammen mit der Texteingabe an das LLM gesendet.
Voyage AI
Voyage AI ist ein Framework, um Embeddings, also Vektoren aus Zahlen, wie oben beschrieben, für RAG erstellen zu lassen. Voyage gehört zu MongoDB und funktioniert natürlich sehr gut mit der Vektorsuche von MongoDB zusammen.
Mithilfe von Voyage wird eine Texteingabe in ein Embedding umgewandelt, zum Beispiel mit folgendem Python-Code:
import voyageai
vo = voyageai.Client()
query = "When is Apple's conference call scheduled?"
query_embedding = vo.embed(
[query],
model="voyage-3.5",
input_type="query").embeddings[0]
Die Frage, die in der Variablen query enthalten ist und typischerweise vom Anwender eingegeben wird, wird mit Voyage in einen Zahlenvektor umgewandelt. Das Ergebnis, also das Embedding, wird in der Variablen query_embedding gespeichert. Die Methode vo.embed(...) verwendet im obigen Beispiel das Embedding-Model voyage-3.5 und das zurückgelieferte Embedding bzw. der Vektor hat dadurch 1024 Dimensionen/Zahlen. Andere Embeddings haben unterschiedliche Dimensionen.
MongoDB
Die Wissensdatenbank, die für RAG verwendet wird, muss einen Vektorindex haben, der natürlich auch mit dem gleichen - zum Beispiel voyage-3.5 - Embedding versehen wurde, wie bei der Erstellung des Embeddings für die Suchabfrage.
Technisch heißt das, dass eine MongoDB Collection mit einem Vector-Search-Index versehen wird.
Wann immer eine RAG-Abfrage durchgeführt werden sollte, werden folgende Schritte in der Software ausgeführt:
- Mit Hilfe der Voyager AI API wird aus der KI-Abfrage des Benutzers ein Embedding gebaut
- Mit Hilfe des obigen Embeddings werden in der entsprechenden MongoDB Datenbank Collection die relevanten Dokumente gesucht, die zur KI-Abfrage passen, durch den Vektor-Search-Index auf der Collection, dann diese Suche effizient ausgeführt werden
- Die KI-Abfrage des Benutzers wird um relevante Informationen aus der Datenbank, die über die vorherige Suche gefunden wurden, angereichert und an das LLM gesendet.
In der obigen Aufzählung habe ich weitere mögliche Schritte, wie zum Beispiel Reranking ausgelassen, um möglichst übersichtlich und einfach zu bleiben.
Fazit
Möchtest du mehr technische Details über MongoDB und RAG wissen, dann folge mir auf LinkedIn. Momentan plane ich einen neuen LinkedIn Kurs zum Thema KI und Datenbanken mit Themen wie RAG.