Docker Model Runner
Ab Version 4.40 kann Docker Desktop KI-Modelle mit dem Befehl docker model run ausführen. Damit ist es nun sehr einfach, LLMs lokal auszuführen und zu testen. Welche Probleme löst dieser neue Docker Befehl und welche nicht?
Das Dateiformat GGUF
Der Docker Model Runner verwendet das GGUF-Dateiformat, das auch von llama.cpp unterstützt wird. Llama ist eine Bibliothek, die als Wrapper für diverse KI-Modelle/LLMs dient. Der Docker Runner verwendet sowohl das Dateiformat, als auch Llama selbst, das im Model Runner integriert wurde. Der Befehl docker model status sagt einem welche Version von Llama intern verwendet wird.
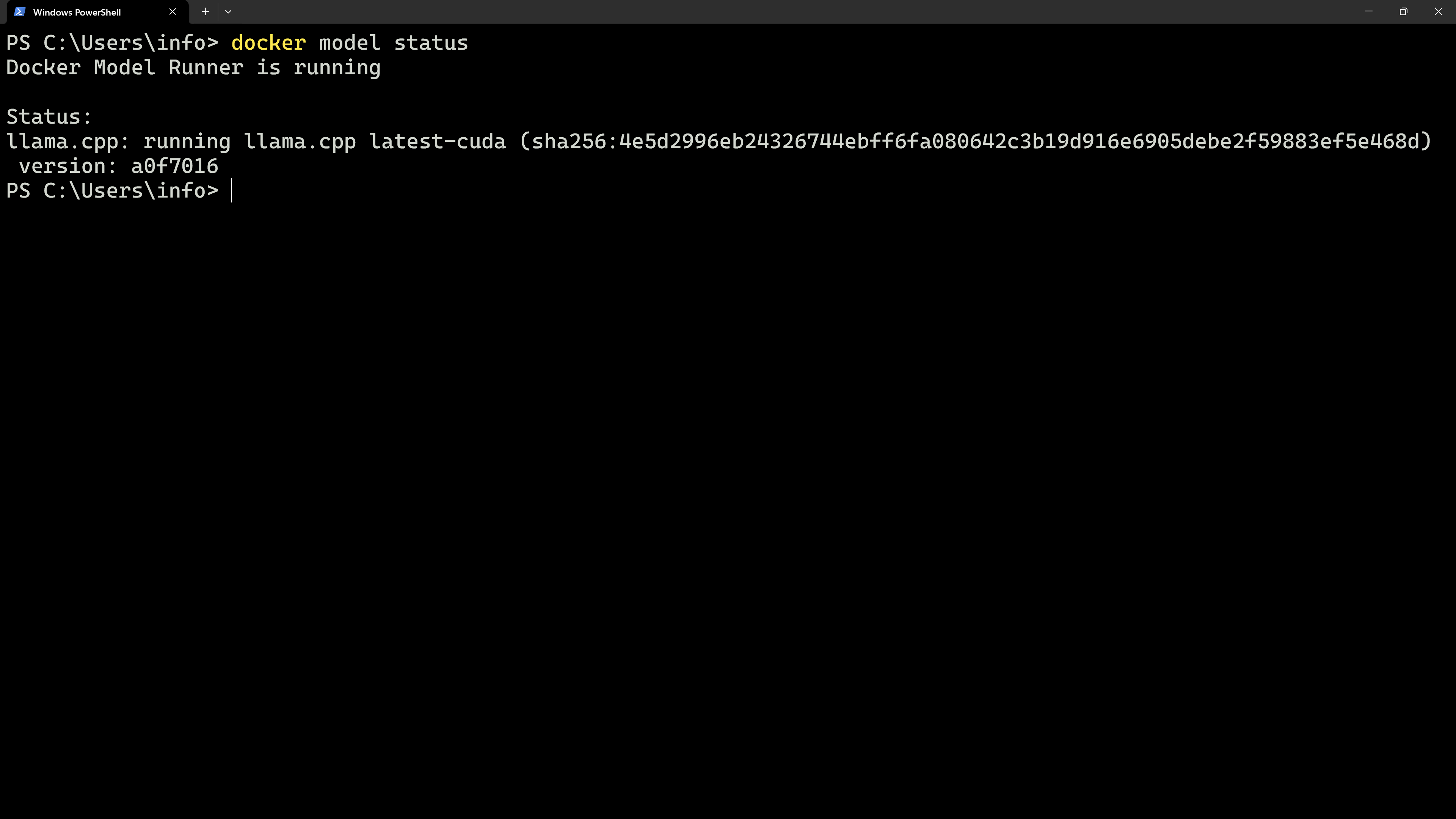
Genau hier liegt jedoch aktuell noch die Schwäche des Docker Model Runners. KI-Modelle werden nicht wie (von mir) erwartet innerhalb von Docker-Containern ausgeführt. Der Befehl docker model ist lediglich ein Aufruf von Llama, das in Docker Desktop integriert wurde.
Auch ohne docker model kann llama jetzt schon innerhalb eines Docker-Containers betrieben werden. Auf Docker Hub befinden sich dazu viele unterschiedliche llama-Images, die mit dem gewohnten Befehl docker container run gestartet werden können. In diesen llama-Containern können KI-Modelle zum Beispiel von Hugging Face heruntergeladen und gestartet werden.
docker model hat momentan mehrere Unterbefehle, wobei der wichtigste docker model run [ai model] ist.
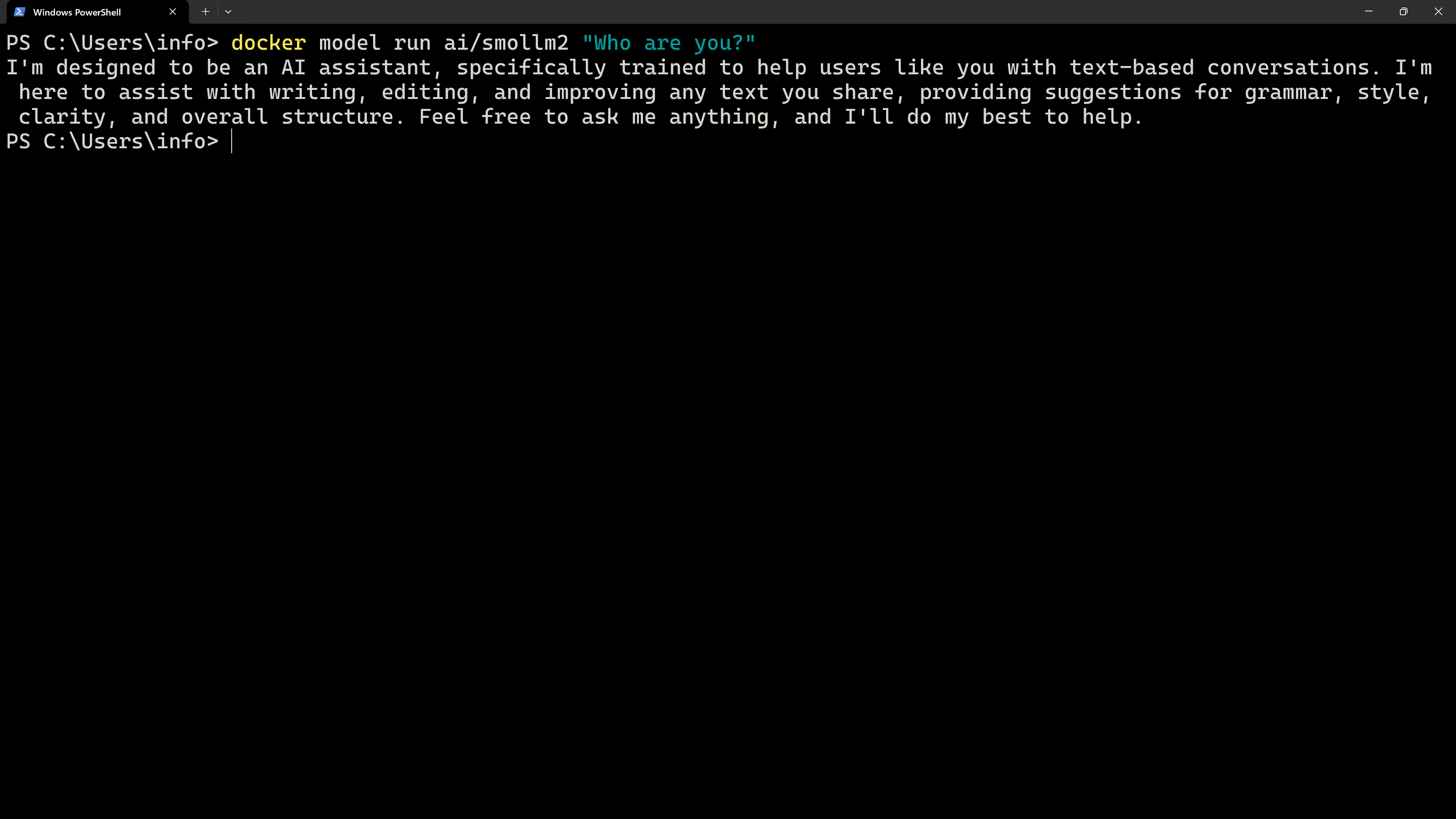
Zum Beispiel wird mit dem Befehl docker model run ai/smollm2 "Who are you?" das KI-Modell ai/smollm2 gestartet und ihm die obige Frage gestellt. Die Antwort des Modells wird einfach auf der Konsole angezeigt.
Die API
Neben einem gemeinsamen Dateiformat für die Modelle bietet der Docker Model Runner auch eine gemeinsame API, die von llama übernommen wurde und wiederum von OpenAI stammt.
Eine Chat-Anfrage kann beispielsweise über den Endpoint http://localhost:12434/engines/llama.cpp/v1/chat/completions mit einem JSON gestellt werden, das mit der OpenAI-API kompatibel ist. Ein HTTP-POST-Request sieht dann wie folgt aus:
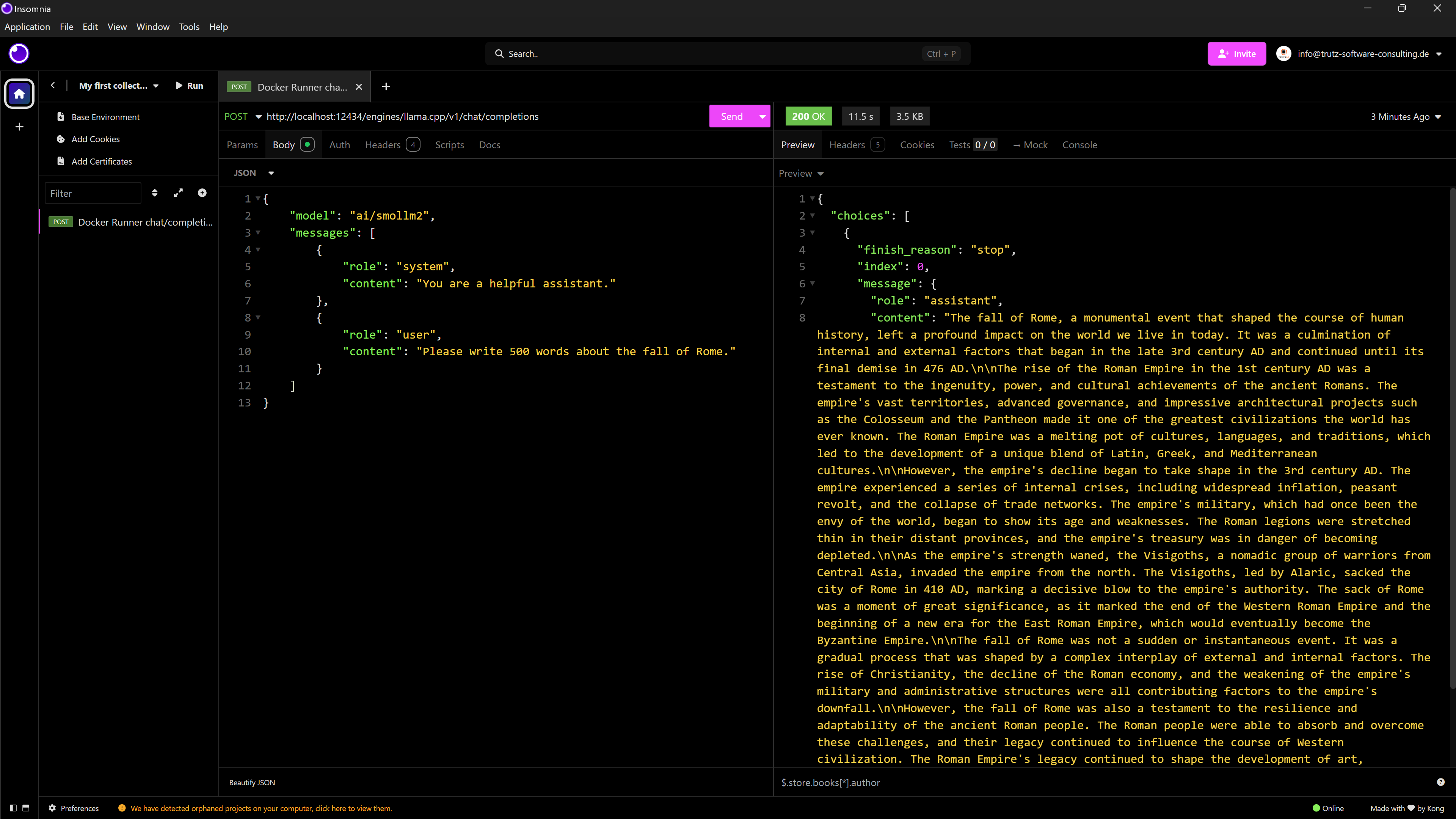
Es ist vorteilhaft, dass Docker Model Runner die bestehende llama/OpenAI-API übernimmt und keine neue aufsetzt. Das bietet Entwickler*innen und Unternehmen eine stabile Basis, mit der auch in Zukunft sehr wahrscheinlich gearbeitet wird.
Fazit
Schnell wird deutlich, dass sich Docker Model Runner noch in der Beta-Phase befindet. Ich hoffe, dass in Zukunft vor allem die Ausführung von KI-Modellen in Docker-Containern unterstützt wird. Eine ausführliche Dokumentation des aktuellen Entwicklungsstands findet man in der offiziellen Dokumentation des Docker Model Runners.